SmartGwt has this great Calendar component to display events, it has many features built in.
Usually you would bind your Calendar to a DataSource and it will fetch, add, update and delete accordingly, but we have a Calendar which data is fetched and updated manually through handlers (DayBodyClickHandler, BackgroundClickHandler, CurrentViewChangedHandler, DateChangedHandler, EventRemoveClickHandler, EventResizeStopHandler) which call event.cancel() to override normal behaviour. It also allows us to display a custom event editing component, although now there exists EventEditorCustomizer. Also you may use a client only DataSource in order to do the filtering locally on client side but we haven’t tried that (though it seems simpler 🤷).
Also I tried to override the shouldShowEvent method but it never was called since we were cancelling the default event handlers.
audienciasCalendar = new Calendar(){
@Override
public boolean shouldShowEvent(CalendarEvent calendarEvent) {
Audiencia audiencia = calendarEvent.getAttributeAsObject("audiencia");
String idJuez = itmJuez.getValueAsString();
if(idJuez != null && !idJuez.equals(audiencia.getJuez().getId())){
return false;
}
return super.shouldShowEvent(calendarEvent);
}
};
So, my solution was to create an array to hold the actual events unfiltered, then when the user changes some SelectItem, it will filter those vaues and call the setData method on the Calendar and hence filtering. To clear the filter we just call setData again with the original values. Also we have to update this variable whenever the user adds, removes or updates an item.
Here the relevant code.
private Calendar audienciasCalendar;
private final SelectItem itmJuez;
private CalendarEvent[] calendarEvents;
...
audienciasCalendar.addDayBodyClickHandler(new DayBodyClickHandler() {
@Override
public void onDayBodyClick(final DayBodyClickEvent event) {
event.cancel();
AudienciaDetailsModule winDetails = new AudienciaDetailsModule();
winDetails.setWidth(Window.getClientWidth() / 2);
winDetails.setHeight(Window.getClientHeight() / 2 + 40);
winDetails.centerInPage();
winDetails.show();
}
});
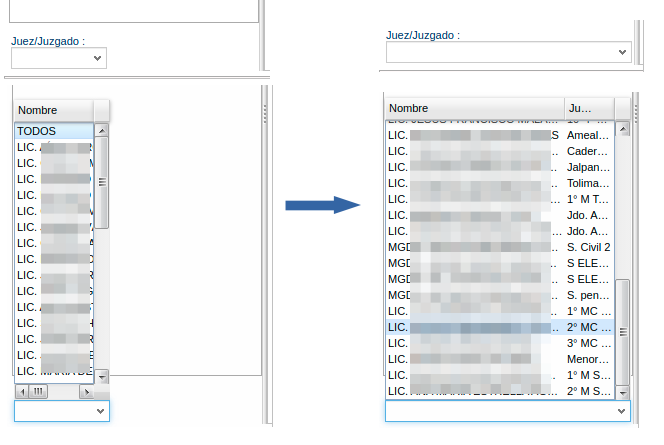
itmJuez = new SelectItem("juez", "Juez/Juzgado");
itmJuez.setOptionDataSource(new RestDataSource(){
{
setDataURL(Consts.REST_JUECES_AGENDA);
setDataFormat(DSDataFormat.JSON);
}
});
itmJuez.setDisplayField("nombre");
itmJuez.setValueField("id");
itmJuez.setAutoFetchData(true);https://www.smartclient.com/smartgwt/javadoc/com/smartgwt/client/docs/ClientOnlyDataSources.html
itmJuez.addChangedHandler(new ChangedHandler() {
@Override
public void onChanged(ChangedEvent changedEvent) {
filterAudiencias((String) changedEvent.getValue());
}
});
private void filterAudiencias(String idJuez) {
if(idJuez != null) {
List filteredEvents = new ArrayList();
for (CalendarEvent calendarEvent : calendarEvents) {
Audiencia audiencia = (Audiencia) calendarEvent.getAttributeAsObject("audiencia");
if (audiencia.getJuez().getId() == idJuez){
filteredEvents.add(calendarEvent);
}
}
audienciasCalendar.setData(filteredEvents.toArray(new CalendarEvent[filteredEvents.size()]));
} else {
audienciasCalendar.setData(calendarEvents);
}
}